
Creating Tests with LLMs
Living life in the fast and buggy lane.


Fig. 1: Is my giraffe smoking? Or eating chalk? Once again we prove that LLMs cannot do math.
This is a followup to my post on using LLMs to perform code reviews, where I used an LLM (Gemini 2.5pro) to do a code review on a RISC-V subroutine which does a fast unsigned integer divide by 5 on processors that lack a divide instruction. I’ve been implementing various algorithms from the book Hacker’s Delight which I cannot recommend enough, as part of this particular routine, I extended the 32-bit algorithm to the 64-bit case so it can also run on 64-bit processors.
To summarize my previous post, I wrote my div5u routine, I got a code review, Gemini told me everything was cool. Then I intentionally broke the code, asked for another code review, and Gemini still said everything was cool. So we know it doesn’t find all the bugs. Here’s my code:
################################################################################
# routine: div5u
#
# Unsigned fast division by 5 without using M extension.
# This routine is 64-bit on 64-bit CPUs and 32-bit on 32-bit CPUs.
# It uses a fast multiply/shift/add/correct algorithm.
# Suitable for use on RV32E architectures.
#
# input registers:
# a0 = unsigned dividend (32 or 64 bits)
#
# output registers:
# a0 = quotient (unsigned)
################################################################################
div5u:
srli a1, a0, 1 # a1 = (n >> 1)
srli a2, a0, 2 # a2 = (n >> 2)
add a1, a1, a2 # a1 = q = (n >> 1) + (n >> 2)
srli a2, a1, 4 # a2 = (q >> 4)
add a1, a1, a2 # a1 = q + (q >> 4)
srli a2, a1, 8 # a2 = (q >> 8)
add a1, a1, a2 # a1 = q + (q >> 8)
srli a2, a1, 16 # a2 = (q >> 16)
add a1, a1, a2 # a1 = q + (q >> 16)
.if CPU_BITS == 64
srli a2, a1, 32 # a2 = (q >> 32)
add a1, a1, a2 # a1 = q + (q >> 32)
.endif
srli a1, a1, 2 # a1 = q = q >> 2 (Final approximate quotient)
# Calculate r = n - q*5
slli a2, a1, 2 # a2 = q*4
add a2, a2, a1 # a2 = q*4 + q = q*5
sub a2, a0, a2 # a2 = r = n - q*5
# Add correction q + (7*r >> 5)
slli a3, a2, 3 # a3 = r*8
sub a2, a3, a2 # a2 = (r*8) - r = r*7
srli a2, a2, 5 # a2 = 7*r >> 5
add a0, a1, a2 # a0 = q + (7*r >> 5)
ret
.size div5u, .-div5u
This is part of my rvint package of RISC-V integer arithmetic algorithms, specifically in the file div.s which contains various division algorithms.
In this episode, I use a cursor to create test cases for my div5u routine. This has its limitations, I’m not totally happy with it. But in this case for the divide by 5 routine, it has two examples for divide by 3 and by 10 in the test routines, so it’s basically going to copypasta some code for me and not do original stuff. For another thing, it always numbers the test cases wrong, and this really isn’t important enough to fix, but I know it’s going to do it (and indeed it does). Here’s how I prompted cursor:
Update div-tests.s with tests for div5u. Use a similar approach as the test cases for div10u and div3u. The routines should test both 32 and 64 bit cases. The tests should test large values in particular because this is where the division approximation is most likely to break down.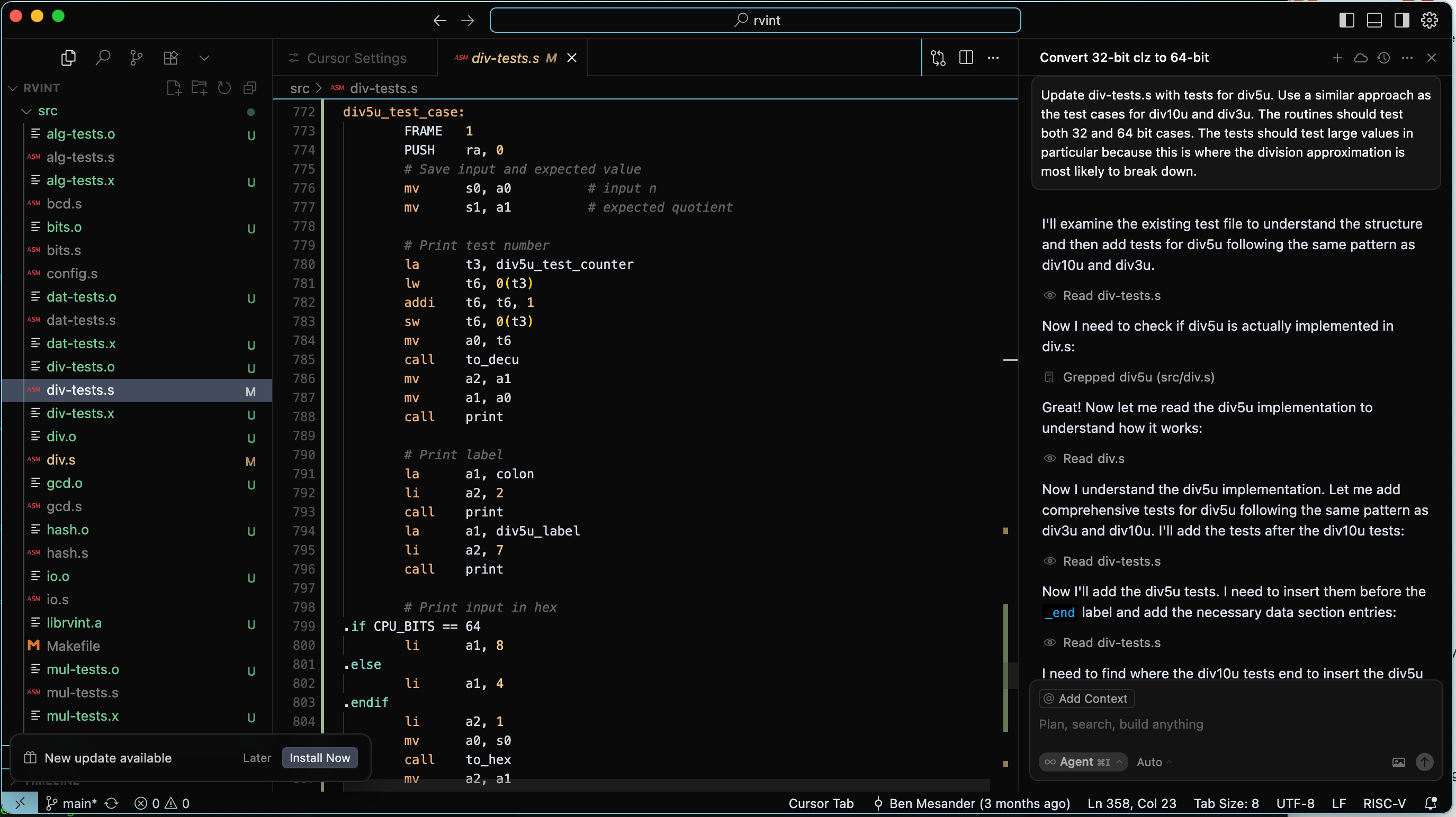
Cursor emits a bunch of gibberish and does its thing and adds a bunch of code to div-tests.s. I assemble and run my code in 32-bit mode on my favorite emulator:
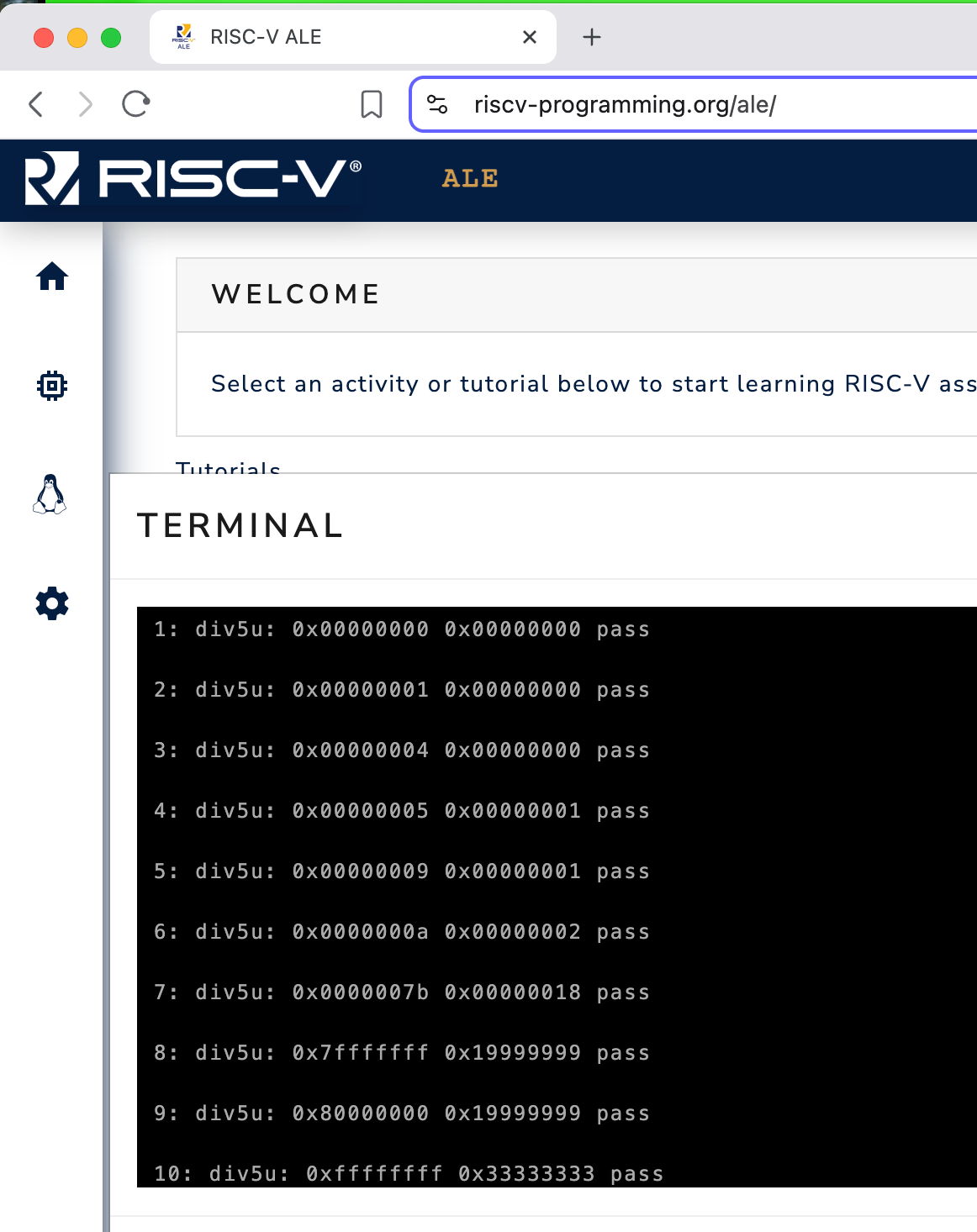
Everything passes! Well so far so good, it’s nice when you write code and it works the first time! Then I log into my 64 bit RISC-V server running on Scaleway and assemble and run my code:
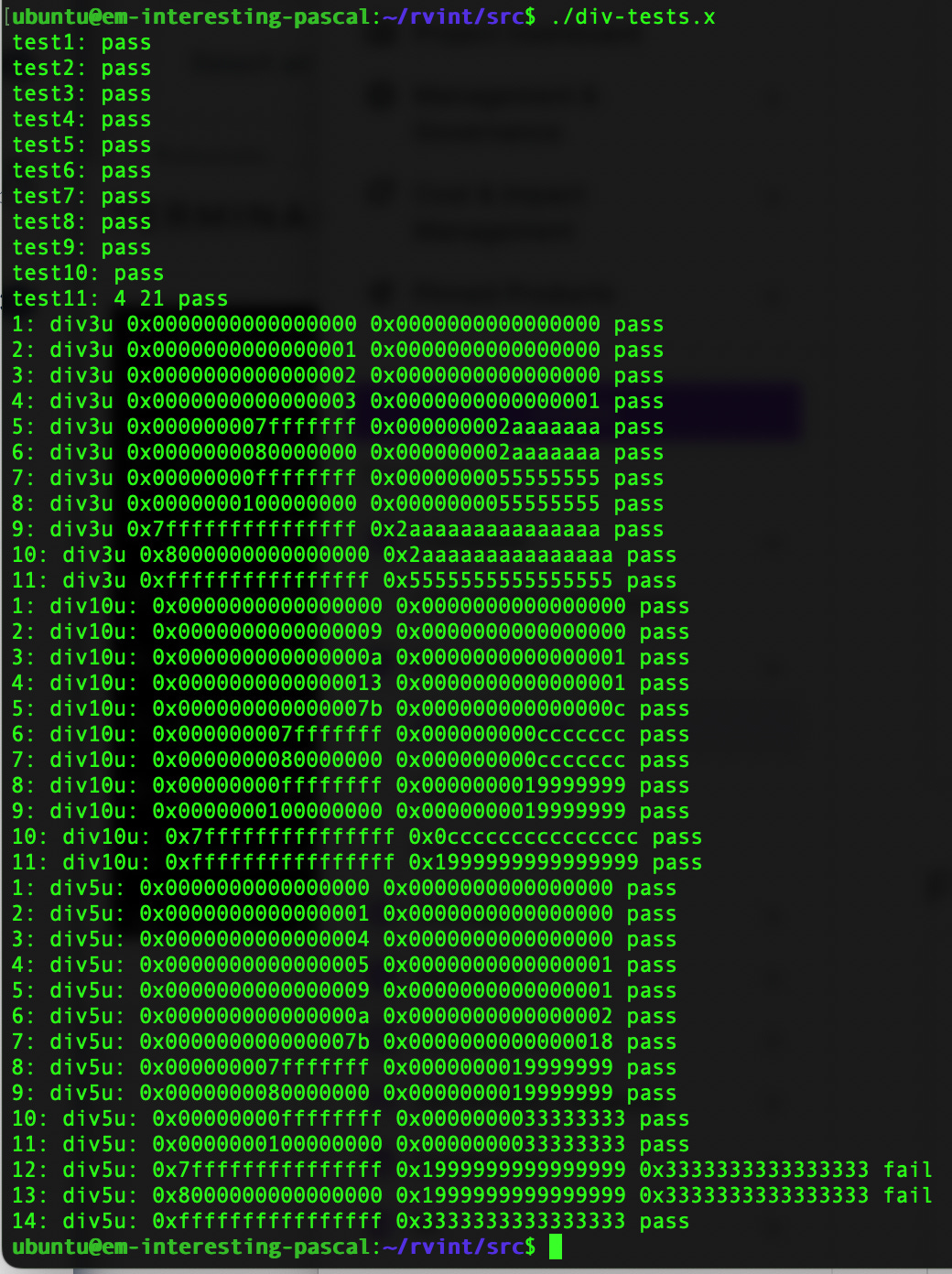
Houston, we have a problem. Now this is interesting, because I expected for mathematical reasons that if I had a failure, only max 64-bit int would have the problem.
We have proven that LLMs can’t do math, so let’s check its work:
ubuntu@em-interesting-pascal:~/rvint/src$ python3
Python 3.12.3 (main, Apr 10 2024, 05:33:47) [GCC 13.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> a=0x7fffffffffffffff
>>> b=0x5
>>> result=a//b
>>> print(hex(result))
0x1999999999999999
>>> a=0x8000000000000000
>>> result=a//b
>>> print(hex(result))
0x1999999999999999
>>>
Well, how bout that. The test case is wrong. Here’s the code that Cursor wrote:
.if CPU_BITS == 64
# 64-bit test cases
# Test 11: 0x100000000 / 5 = 0x33333333
li a0, 0x100000000
li a1, 0x33333333
call div5u_test_case
# Test 12: 0x7fffffffffffffff / 5 = 0x3333333333333333
li a0, 0x7fffffffffffffff
li a1, 0x3333333333333333
call div5u_test_case
# Test 13: 0x8000000000000000 / 5 = 0x3333333333333333
li a0, 0x8000000000000000
li a1, 0x3333333333333333
call div5u_test_case
# Test 14: 0xffffffffffffffff / 5 = 0x3333333333333333
li a0, -1
li a1, 0x3333333333333333
call div5u_test_case
.endif
So let’s correct it:
.if CPU_BITS == 64
# 64-bit test cases
# Test 11: 0x100000000 / 5 = 0x33333333
li a0, 0x100000000
li a1, 0x33333333
call div5u_test_case
# Test 12: 0x7fffffffffffffff / 5 = 0x1999999999999999
li a0, 0x7fffffffffffffff
li a1, 0x1999999999999999
call div5u_test_case
# Test 13: 0x8000000000000000 / 5 = 0x1999999999999999
li a0, 0x8000000000000000
li a1, 0x1999999999999999
call div5u_test_case
# Test 14: 0xffffffffffffffff / 5 = 0x3333333333333333
li a0, -1
li a1, 0x3333333333333333
call div5u_test_case
.endifand when we assemble and run the code, now it works correctly:
ubuntu@em-interesting-pascal:~/rvint/src$ ./div-tests.x
test1: pass
test2: pass
test3: pass
test4: pass
test5: pass
test6: pass
test7: pass
test8: pass
test9: pass
test10: pass
test11: 4 21 pass
1: div3u 0x0000000000000000 0x0000000000000000 pass
2: div3u 0x0000000000000001 0x0000000000000000 pass
3: div3u 0x0000000000000002 0x0000000000000000 pass
4: div3u 0x0000000000000003 0x0000000000000001 pass
5: div3u 0x000000007fffffff 0x000000002aaaaaaa pass
6: div3u 0x0000000080000000 0x000000002aaaaaaa pass
7: div3u 0x00000000ffffffff 0x0000000055555555 pass
8: div3u 0x0000000100000000 0x0000000055555555 pass
9: div3u 0x7fffffffffffffff 0x2aaaaaaaaaaaaaaa pass
10: div3u 0x8000000000000000 0x2aaaaaaaaaaaaaaa pass
11: div3u 0xffffffffffffffff 0x5555555555555555 pass
1: div10u: 0x0000000000000000 0x0000000000000000 pass
2: div10u: 0x0000000000000009 0x0000000000000000 pass
3: div10u: 0x000000000000000a 0x0000000000000001 pass
4: div10u: 0x0000000000000013 0x0000000000000001 pass
5: div10u: 0x000000000000007b 0x000000000000000c pass
6: div10u: 0x000000007fffffff 0x000000000ccccccc pass
7: div10u: 0x0000000080000000 0x000000000ccccccc pass
8: div10u: 0x00000000ffffffff 0x0000000019999999 pass
9: div10u: 0x0000000100000000 0x0000000019999999 pass
10: div10u: 0x7fffffffffffffff 0x0ccccccccccccccc pass
11: div10u: 0xffffffffffffffff 0x1999999999999999 pass
1: div5u: 0x0000000000000000 0x0000000000000000 pass
2: div5u: 0x0000000000000001 0x0000000000000000 pass
3: div5u: 0x0000000000000004 0x0000000000000000 pass
4: div5u: 0x0000000000000005 0x0000000000000001 pass
5: div5u: 0x0000000000000009 0x0000000000000001 pass
6: div5u: 0x000000000000000a 0x0000000000000002 pass
7: div5u: 0x000000000000007b 0x0000000000000018 pass
8: div5u: 0x000000007fffffff 0x0000000019999999 pass
9: div5u: 0x0000000080000000 0x0000000019999999 pass
10: div5u: 0x00000000ffffffff 0x0000000033333333 pass
11: div5u: 0x0000000100000000 0x0000000033333333 pass
12: div5u: 0x7fffffffffffffff 0x1999999999999999 pass
13: div5u: 0x8000000000000000 0x1999999999999999 pass
14: div5u: 0xffffffffffffffff 0x3333333333333333 pass
ubuntu@em-interesting-pascal:~/rvint/src$
In addition to the bugs, the LLM did some other silly things, the order of tests in the div-tests.s file is now divide by 3, divide by 10, divide by 5. I would have done them in the order 3, 5, 10. Similarly some variables in the data segment just got appended to the end, instead of being grouped with similar variables. I didn’t care enough to try to adjust my prompt to try to fix this; next time I’m editing the file for some other reason, I’ll clean it up.
So again, trust but verify. The LLM did save me some time writing test cases, but it got 2 out of the 14 test cases it wrote wrong. The code it wrote was sloppy. Overall, it saved me some time, but I’m always a little disappointed.